Cross-Task Transfer for Geotagged Audiovisual Aerial Scene Recognition
ECCV 2020
Authors: Di Hu, Xuhong Li, Lichao Mou, Pu Jin, Dong Chen, Liping Jing, Xiaoxiang Zhu, Dejing Dou
Brief Introduction
The AuDio Visual Aerial sceNe reCognition datasEt (ADVANCE) is a brand-new multimodal learning dataset, which aims to explore the contribution of both audio and conventional visual messages to scene recognition. This dataset in summary contains 5075 pairs of geotagged aerial images and sounds, classified into 13 scene classes, i.e., airport, sports land, beach, bridge, farmland, forest, grassland, harbor, lake, orchard, residential area, shrub land, and train station. We hope this dataset can help to facilitate the research in aerial scene understanding and audiovisual learning.
Audiovisual samples
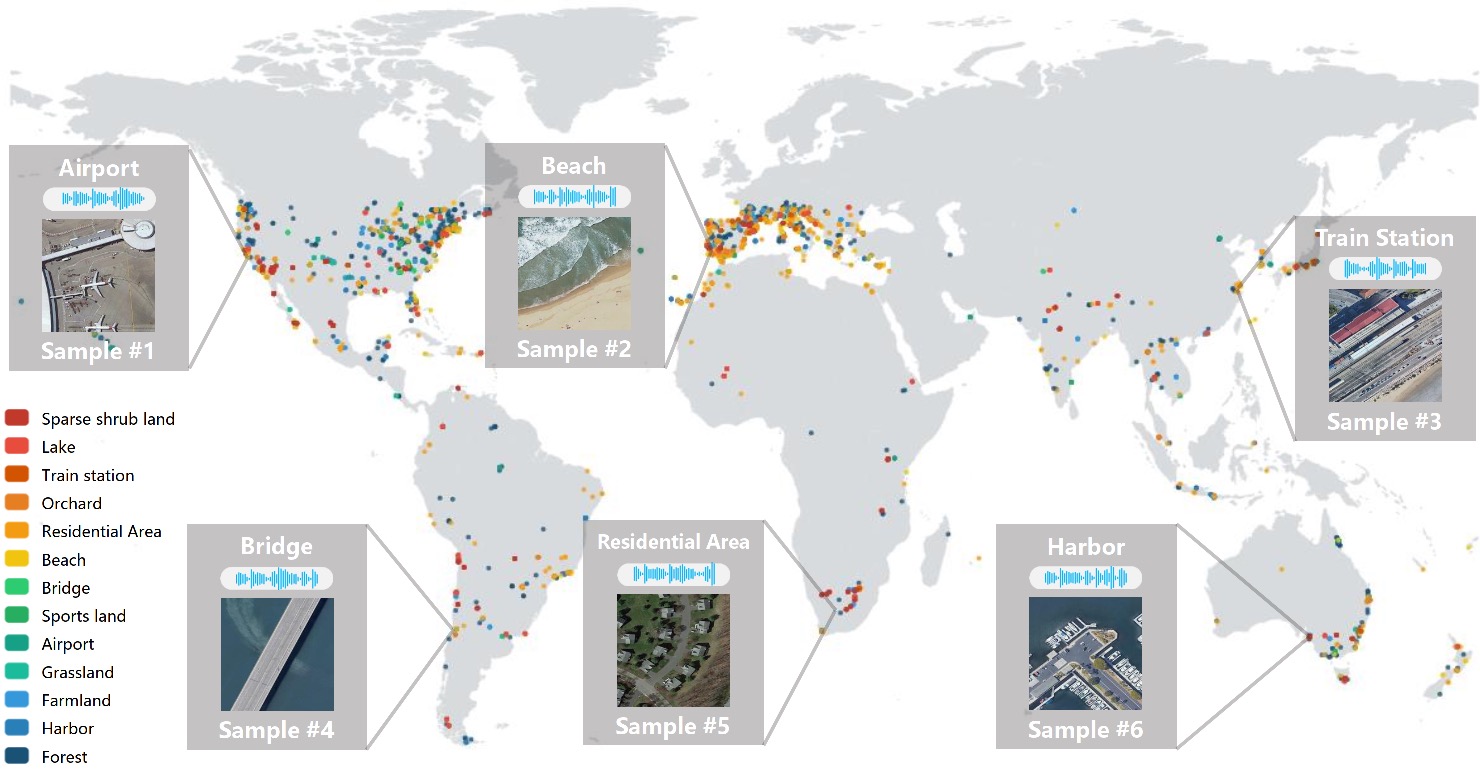 Global coordinates distribution and sample pairs of images and sound. Different scenes are represented by different color. Six sample pairs are displayed, which are composed of aerial images, sound and semantic labels.
Global coordinates distribution and sample pairs of images and sound. Different scenes are represented by different color. Six sample pairs are displayed, which are composed of aerial images, sound and semantic labels.
Dataset collection
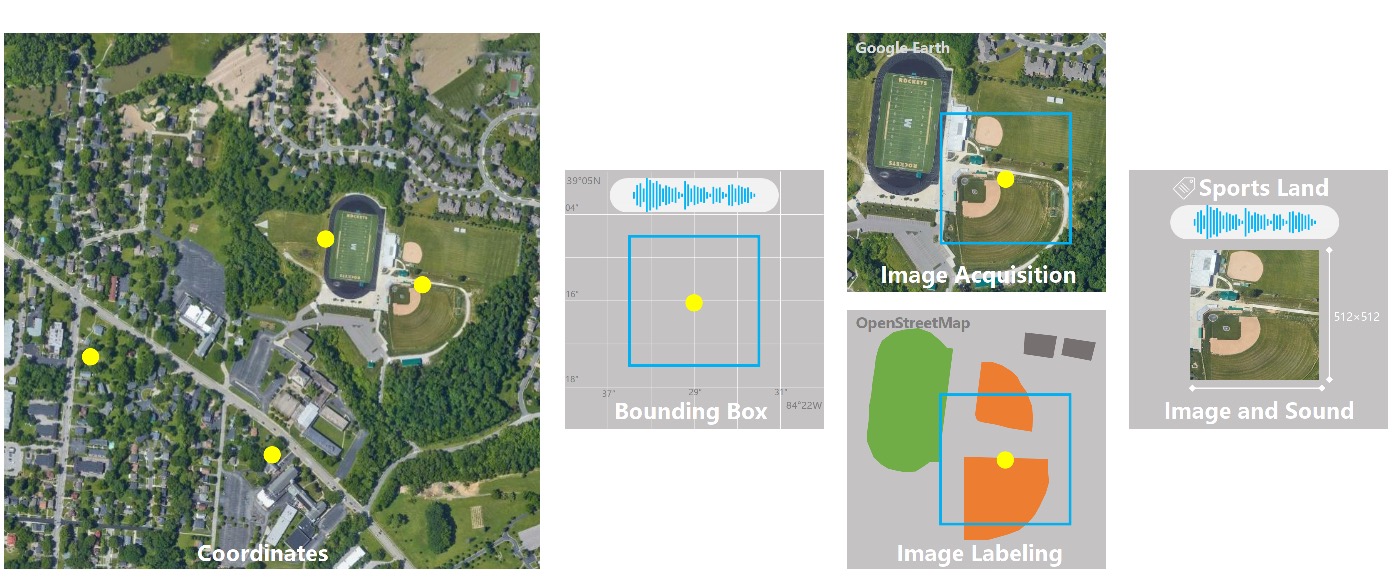 The audio data are collected from Freesound, where we remove the audio recordings that are shorter than 2 seconds, and extend those that are between 2 and 10 seconds to longer than 10 seconds by replicating the audio content. Each audio recording is attached to the geographic coordinates of the sound being recorded. From the location information, we can download the updated aerial images from Google Earth. Then we pair the downloaded aerial image with a randomly extracted 10-second sound clip from the entire audio recording content. Finally, the paired data are labeled according to the annotations from OpenStreetMap, also using the attached geographic coordinates from the audio recording. Those annotations have manually been corrected and verified by participants in case that some of them are not up to date.
The audio data are collected from Freesound, where we remove the audio recordings that are shorter than 2 seconds, and extend those that are between 2 and 10 seconds to longer than 10 seconds by replicating the audio content. Each audio recording is attached to the geographic coordinates of the sound being recorded. From the location information, we can download the updated aerial images from Google Earth. Then we pair the downloaded aerial image with a randomly extracted 10-second sound clip from the entire audio recording content. Finally, the paired data are labeled according to the annotations from OpenStreetMap, also using the attached geographic coordinates from the audio recording. Those annotations have manually been corrected and verified by participants in case that some of them are not up to date.
Data statistics
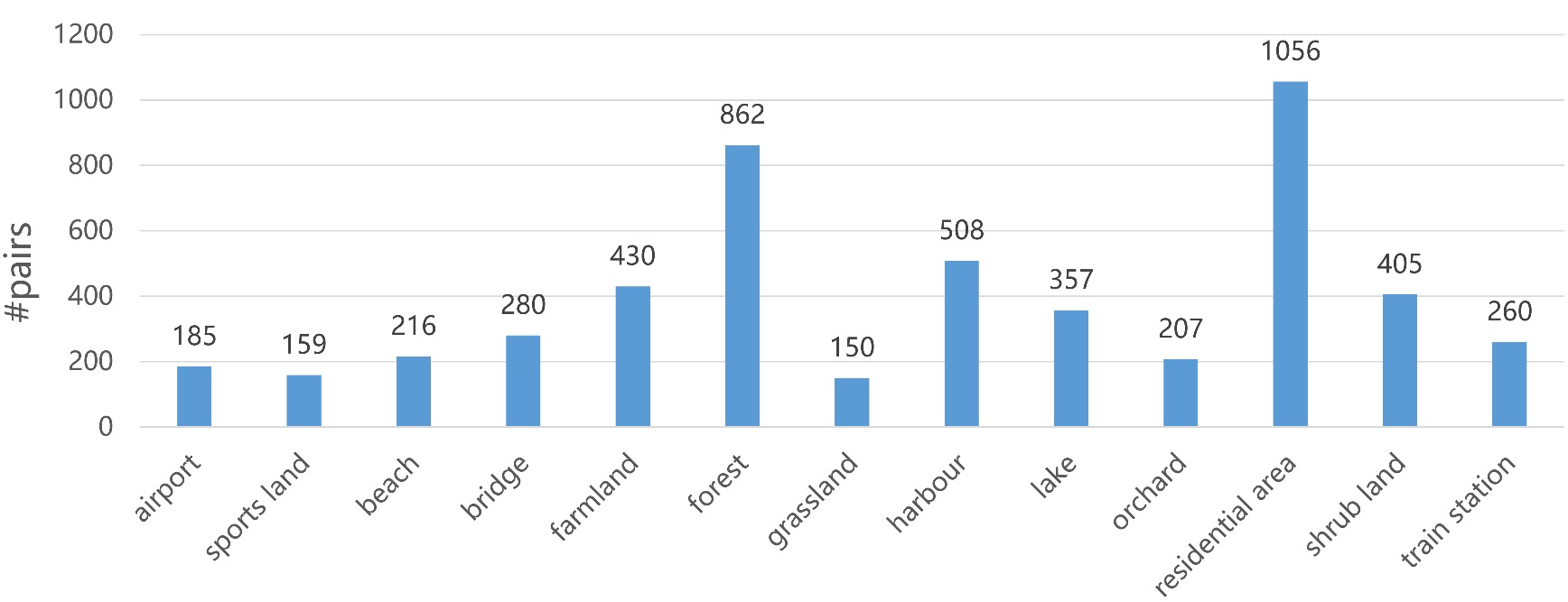 Due to the inherent uneven distribution of scene classes, the collected data are strongly unbalanced, which makes difficult the training process.
So, two extra steps are designed to alleviate the unbalanced-distribution problem. Firstly we filter out the scenes whose numbers of paired samples are less than 10, such as desert and the site of wind turbines. Then for scenes that have less than 100 samples, we apply a small offset to the original geographic coordinates in four directions. So, correspondingly, four new aerial images are generated from Google Earth and paired with the same audio recording, while for each image, a new 10-second sound clip is randomly extracted from the recording.
Due to the inherent uneven distribution of scene classes, the collected data are strongly unbalanced, which makes difficult the training process.
So, two extra steps are designed to alleviate the unbalanced-distribution problem. Firstly we filter out the scenes whose numbers of paired samples are less than 10, such as desert and the site of wind turbines. Then for scenes that have less than 100 samples, we apply a small offset to the original geographic coordinates in four directions. So, correspondingly, four new aerial images are generated from Google Earth and paired with the same audio recording, while for each image, a new 10-second sound clip is randomly extracted from the recording.
Spliting strategy
The dataset was splited by train/Val/test with the ratio of 0.7:0.1:0.2. Data construction fashion
Download
Reference
If you use the paper repo or the ADVANCE dataset in your research, please cite our paper:
Cross-Task Transfer for Geotagged Audiovisual Aerial Scene Recognition
Di Hu, Xuhong Li, Lichao Mou, Pu Jin, Dong Chen, Liping Jing, Xiaoxiang Zhu, Dejing Dou
ECCV 2020